
(Date of Last Revision: January 9, 2024)
Contents
Countering Fake, Understated, or Altered Data
Abstract
This white paper delves into the real-world problem of verifying file trustworthiness. It identifies the challenges inherent in durably and accurately proving that files existed at a specific date and time, and that they are verifiable (without divulging the contents of those files). This document explores the significance of combining the deployment of file hashes as unique identifiers with distributed, immutable, and tamper-proof ledgers to prove ownership; thwart backdating, file tampering, and some types of fraud; and validate authenticity. This paper also provides a brief, upfront introduction to the technology we (the authors and the founders of ChainLetter Labs) are continuing to develop to address the real-world issues discussed herein.
Our Technology in Brief
ChainLetter Labs has developed a proprietary technology that combines traditional means of file management and file sharing with blockchain based enhancements—based primarily on blockchain file inscription and a privately developed offline hashing algorithm—in order to create simple, tamperproof tools for file verification (i.e., proving that the file in question is original and has not been tampered with), proof of possession, and more. Our technology enables a wide range of use cases. Examples include but are not limited to: authors can assert ownership of their IP by uploading original manuscripts; video bloggers can upload their content by way of demonstrating they “had their idea first” when facing impersonation; military personnel from two separate nations can upload their briefs, operations orders, etc. and can cross-reference the files such that they can ensure the information they are sharing has not been tampered with and is from the appropriate source (and not a bad actor impersonating the source of the information); accounting firms can create time-stamped, verifiable, and tamper-proof financial statements (or request Postmarked statements) to ensure appropriate files are being used in preparing or conducting an audit. Furthermore, our technology allows for this file verification information to be made publicly available, with or without divulging the actual contents of the files, and, if desired, without ever exposing the file contents to online environments (in other words, file contents can remain offline and private). These characteristics become particularly important in a number of use cases that will be discussed further.
ChainLetter Labs is developing this technology into products that everyday consumers can use for a variety of use cases. The most basic product is called “Postmarks,” which can be used by individual consumers (like in the writer or video blogger examples), all the way up to enterprise organizations (e.g., university registrars could, at a fraction of the cost of today’s methods, Postmark official transcripts, that could then be called upon later to fulfill student/ former student requests for transcripts, or requests from third parties who want to verify the transcripts they received are in fact original and not fraudulent—important in hiring, background checks, applications, etc.). We are also layering this technology into other software platforms beyond a relatively simple Postmarks site, such as a publishing-services platform, which provides a greater suite of tools for publishers and writers to not only Postmark their work, but also to publish, market, and sell their work.
Technology Applications
We have identified three primary applications under which use most cases satisfy at least two of the three that can add significant value to the file(s) in question:
-
- Proof of possession: Verifiable possession over the given file(s) at a specific date/ time, such as an original recording or manuscript.
-
- Tamper resistance: File(s) can be cross referenced against the originally Postmarked file to verify nothing has changed since time of being Postmarked, such as audited financial statements.
-
- Authenticity of original file:
-
- Data recorded in real time, such as video camera footage, that is Postmarked in real-time (or near real-time), that becomes essential in matters of dispute. Or,
-
- Data/ file(s) issued by an issuing authority that must be verified as original at a later date, such as identification cards, transcripts, car titles, etc.
-
- Authenticity of original file:
So that readers may keep some examples in mind while we delve further into our technology, we provide this non-exhaustive, preliminary list of sample use-cases for which this technology may add value or solve critical problems:
-
- Digital identification cards, vaccine cards, passports etc. (where users carry file from issuing authority on digital device)
-
- Original creator content (music, video, manuscripts, art)
-
- “Do Not Train” AI database *requires industry/ third party buy-in (discussed further herein)
-
- Security camera footage
-
- Bodycam footage, car mounted video, etc. *would require hardware/ issuing authority to employ Postmarks tech
-
- Official records issued by third party verifier (transcripts, car titles, wills, audited financials etc.)
-
- Research findings, lab results, test data
-
- Audited financials or company provided financial statements
-
- Student papers, dissertations, theses, etc.
-
- Agent queries/ book proposals
-
- Certified copies/ letters
-
- Portable medical records
-
- Insurance documentation
-
- Estate documents
-
- Real estate / home inspection
-
- Court evidence
-
- Landlord/ tenant disputes
The focus of this paper is on the underlying technology to Postmarks and the value therein. That said, ChainLetter Labs is developing several other complimentary technologies in conjunction with Postmarks; some for the purposes of the aforementioned software platforms, and others, which could also be standalone products. Our current limitations in expanding our target userbase, use-case portfolio, and product suite are in our manpower and funding resources; therefore we have been and—until we have more resources to grow and scale more rapidly—will continue to be, selective with the release of our technology (to what target markets, and for what use cases). That said, the potential and global impact of this technology cannot be understated, nor can its potential to rapidly scale. Especially in a world of increased, frequent use of AI, we envision a world in which Postmarking important files becomes a normalized part of the file/ content/ information creation, sharing, and cataloging processes, i.e. “don’t forget to Postmark your work.”
It is worth noting that while our technology is blockchain agnostic, for our initial stages, ChainLetter Labs has built its early-stage technology and associated products using the WAX blockchain, not only for its utility and cost-effectiveness in achieving our technology objectives, but—arguably most importantly—because of WAX’s commitment to carbon neutrality.
Basic Scenario
In the digital realm, establishing the uniqueness of any file poses a myriad of challenges, demanding a nuanced understanding of computational principles. By way of introducing the concepts discussed herein, we present a realistic scenario in which one could usefully and practically employ the technology being discussed. It is worth noting that in this scenario, the technology we have developed could be employed today to achieve the desired effect, with little-to-no further development.
Note: in the unlikely event that our example scenario has likeness to a scenario taking place in the real-world, this is a matter of coincidence—we simply made this scenario up for the purposes of conveying the concepts covered within this paper.
Imagine you sit down at your computer and open the notepad application. You type the phrase, “Hello,” and save the file. Now, your friend in another location does the same thing. Are these the same file? Does it matter how the file was produced?
Now, let’s redefine a file as the bytes representing the data in the file, and not any of the metadata added by the operating system (modified date, file name, etc.). Under that consideration, the two “Hello” text files are identical.
If you’re tasked with proving who created their file first, and who has the best claim over the “Hello” text, options are limited. You can argue about who you think typed it first, who saved the file first, whether this is the first time you created this file, whether you can view the modified date, or whether there are any cloud backups. Your evidence consists of the metadata added by each computer, which are easily modified by changing the system clock or by editing the data directly (among other methods).
In essence, applying the most commonly available methods today to this simple scenario, there is no clear way of proving who created the file first, and one must decide who has the more convincing claim in a non-scientific fashion. Most of the metadata we can access are prone to errors, rely on trusting a third party, or are susceptible to fraud or deletion. These methods are discussed in more detail below.
Current Techniques and Procedures for Verifying File Trustworthiness and Proof of Possession, and Associated Drawbacks
In the previous section, we introduced the “Hello” text scenario, in which two parties challenge one another for a claim to “who typed the word ‘Hello’ first.” Below is a brief analysis of current methods and procedures for obtaining or creating verifiable “truth” or proof of ownership in this scenario, and associated concerns, such as negative security implications. This list is non-exhaustive; these are just some examples of frequently used methods.
Email Backups
If one happens to have emailed oneself the file before the argument ensues, they may have a better claim, but the email itself is exposed to a number of faults based on service provider, servers, connectivity, etc. For instance, the email could be deleted from the server, or the author could lose access to it. This proof also relies on the email provider maintaining good records and should be considered brittle.
Public Release of Information and Third-Party Recordkeeping
Other previous “best” options have been 1) the public release of the contents of any file we need to prove we own, as if to create witnesses or establish claim or 2) relying on third-party recordkeeping from organizations or institutions, (e.g., government archives, private file services). These options are typically inconvenient, rely on other parties as witnesses and to maintain neutrality if ownership is contested, or are costly such that they are out of scope for a large portion of use cases (e.g., video bloggers or writers wanting to save original manuscripts or content). Not to mention, they are of questionable security and typically require that the contents of files be uploaded to a third-party server or cloud-services provider.
Some examples of high-profile data leaks by third-party data managers include the 2015 Office of Personnel Management breach in which adversarial actors targeted US Government SF-86 forms (used by personnel undergoing security clearance screenings) as a means of accessing personally identifiable information and data that could be used to cause great damage, and the 2017 Equifax Data Breach, in which the private data of tens of millions of Americans, British, and Canadians were compromised. Essentially, the third-party actors we often believe are the most trustworthy with our personal data (or have no choice but to transmit such data in online environments) are the most vulnerable. In fact, as in the case of the OPM and Equifax examples, centralized third party systems are often the most vulnerable. In today’s environment where bad actors have cheaply and readily available access to the means to conduct file tampering and fraud, consumers should not rely on third parties to store and protect their valuable data, especially that which requires ongoing verification. Sensitive digital information stored locally with limited exposure to online environments may be more secure than information that is stored and/ or frequently touches online ecosystems.
Moreover, if desired, our technology could be used as an enhancement to, not a replacement for, these methods. A YouTube influencer could post their video and simultaneously Postmark their content, so that if their content is taken down and another user or impersonator reposts the content, the original party will have verifiable proof of possession at a date preceding that of the bad actors (this is one of the specific use cases we have had in mind in developing a Postmarks site specifically for YouTubers: https://testyoutube.chainletter.io).
Screenshots and Other Content Recorded in Real Time
Screenshots are often used as “proof” that messages were sent, or that text was posted or transmitted (via email, social media, etc.). Banks frequently ask for screenshots to verify real-time account balances during underwriting processes. These are easily manipulated using readily available image editing software. And, because they are created by an untrusted local device, they cannot serve as means of durable proof. A hardware/ software integration (e.g. in the form of an iOS app) that allows for photos, screenshots, etc. to be instantaneously Postmarked upon creation could create durable and authentic proof of information as it is happening in real-time. (Note that while we have contemplated working on this, we would need more resources to build and implement such an application/ integration.)
In addition to still-imagery, we often rely on video content recorded in real-time, like CCTV (security camera) footage, as evidence. Having these files stored in the cloud is one step closer to durability, but then one is again relying on a third party like Amazon to vouch for the integrity of the files. Plus, the files could be deleted or tampered with at any time, since they are outside of the original owner’s control (or in some cases, the problem is the “original owner” or first person with possession in the chain of custody—if that person is in a position in which they can tamper with the data for nefarious purposes).
For example, the use of bodycams in law enforcement continues to grow, and such footage can be used in identifying inappropriate behavior or conduct on behalf of parties counter to law enforcement, or law enforcement officials themselves. We believe there is a strong use case for our technology in bodycam and security camera footage; footage recorded real time could be Postmarked almost instantaneously to prevent tampering and could then be reverified as original should the content be needed for as proof, with a chance of collision at 2^256 (discussed below)–undoubtedly durable in the court of law.
In summary, current local solutions give too many opportunities for tampering to be trustworthy. There is a need to “freeze” a file in time, and then document only the minimum amount of anonymous data required to durably prove the contents of the file(s) in question, and the creation date, without divulging any of the sensitive information within, whether an influencer’s high-value intellectual property (IP), a company’s trade secrets, a lab technician’s test results, or a military unit’s photographic evidence, for example video camera, drone, or satellite footage, that might be used for attribution in engaging in armed conflict. Postmarks can also serve to verify “air-gapped” files which are not online, and therefore un-hackable (e.g. one could store files / records onto a USB drive, and the Postmarks will still prove their contents).
ChainLetter Labs’ Methodology
-
- Separating Proof from the File Itself
The first challenge in creating provenance for files is creating a minimum amount of metadata representing that file. We can derive or add our fields by using our definition of a file as the bytes making up the file’s content, rather than the operating system’s file record. Our needs are different from an operating system; we need to be able to search by these derived fields, but they do not need to be human readable (like a file name). We also do not need to record things like file size, since it is evident from the length of the bytes. For reasons that become apparent later, we need to be able to pack this data into integer types as tightly as possible to minimize the size and cost of the metadata.
This leaves our proof at:
-
- A cryptographic hash of the file with the chance of collision at 2^256 (CIDv0 algorithm from IPFS)
-
- A second, optional file hash using a different mechanism from the first to further decrease the chance of collision (SHA256 or similar)
-
- A GUID (globally unique ID) representing the person or entity staking a claim to this data
-
- An optional server timestamp (Unix Epoch) showing the metadata creation time
-
- The blockchain timestamp, which we have no control over, but which is the official creation time
Tools exist for every major operating system to calculate these hashes offline and in secure environments. They are easily verifiable by anybody familiar with cryptography.
An example proof package in JSON format looks like:
{
cid: “QmPNXpGz61ihgAZugxSDwXqCGJ265uuyzVrb9ZFyKkp85F”,
uid: “4f885229-2ef2-4046-8bf3-2fe043a77773”,
date: 1684811930479
}
This can all be compacted into integers for later inclusion in blockchain data.
-
- Making the Proof Durable with the Blockchain
For our proof to endure, we must ensure it is not vulnerable to deletion by whoever is storing it. It needs to be safe from hackers and governments. Until recently, this wasn’t easy to achieve, and we have been forced to rely on the reputation of digital archive services.
Blockchains solve this issue for us. By being distributed and cryptographically verifiable, tampering becomes difficult on any blockchain. We can rely on the anonymity and consensus mechanism of the blockchain to keep our proofs in trust for the lifetime of those chains. Storing the same proof data on multiple chains can further increase defenses against consensus attacks on any hosting blockchains.
Our technique is not based on any specific blockchain technology. Whether Bitcoin Inscription, Ethereum contracts, Flow by Dapper, WAX Collectibles, or Monero, it makes no difference, so long as the proof data can be added to a block upheld by the block producers on that chain.
In short, we are simply using blockchain as an immutable distributed ledger.
-
- Allowing Public Access to the Proof
Blockchain explorers exist and are publicly available on all major blockchain networks. The specifics vary by chain, but all the data is indexable by any history node operator.
Because of this, we rely on blockchain explorers, market websites, and wallet software as independent third parties who act as witnesses to the validity of our proof data.
Using enough of these third parties creates compelling evidence that the data is correct without the need to cryptographically validate all the blocks on the blockchain ourselves. Because these third parties have no stake in the outcome of our validation process, they are much more likely to be truthful.
-
- Verifying a Proof
Because the bytes in the file are in a one-to-one relationship to the unique CID representing the file, it can be verified offline in a secure context.
Our prototype uses a javascript implementation that does all the calculations in the user’s web browser using an offline background process. The same could easily be done in many programming languages and tools used in most major operating systems to calculate file hashes.
If one knows one or more gateway URLs for the blockchain records, one can easily compare locally calculated results to what is on a chain, without divulging the contents of the file or record in question.
If a file will intentionally be shared publicly, it can be uploaded to any IPFS pinning service1 for immediate global distribution using the same calculated CID.
The main caveat to verifying a proof is that the file bytes must never change (or one needs a new proof). We can “freeze” files more easily by storing them in a compressed zip archive when the initial proof is created.
First Proof of Possession
For the purposes of this paper, we define “first proof of possession,” as a Postmark of a file that can be used to verify possession of said file at any given time. While this does not necessarily mean the person who Postmarked the file (and therefore its contents) created the file, it does publicly and immutably verify possession of that exact file/ content at a specific date and time, and also verifies the file as having not been tampered with as compared to another file allegedly containing the same content created at a different date and time (either before or after the Postmarked file).
Among other use cases, such as thwarting imitation/ plagiarism of original IP for profit, we also believe that asserting ownership by registering file hashes and creating “first proof of possession” is a durable defense against the ever-increasing use of AI training technology. As such, we have created a prototype mechanism for searching registered file hashes in a “do not train” database. While this technology is in early stages and requires further development, we believe such a database could prove powerful in a number of use cases, particularly in maintaining control over one’s IP for artists, musicians, creators.
Again, our proofs do not provide any new means of recognizing IP ownership, but claiming possession of a file at a specific time remains a powerful tool, especially without necessarily or reluctantly having to publicly release the contents of the file in making a claim.
Example: Masters (Music)
Imagine you downloaded an MP3 of a Taylor Swift song. Nothing is preventing you from creating proof that you possess that MP3. It does not suddenly give you rights to the music. It does not even prove you listened to the song.
In other words, the value one gets from proving one possesses a file that does not belong to them is minimal.
Instead, let’s imagine Taylor Swift’s record label created a proof from the master of her unreleased song using a Postmark. Since this song is not yet publicly available, it gives Taylor a solid claim to being the originator of the lyrics and melody in that song.
While copyright is granted upon creation (for the purposes of this example; copyright law is beyond the scope of this paper), the song may go unreleased for some period of time. And if the track’s copyright is infringed upon, whether or not the song is released, Taylor Swift’s team could use the Postmark in, say, a DMCA takedown notice as proof of the song’s origins, since there would not be proof otherwise, especially prior to the public release of the song. In this example, the Postmark acts as a copyright enhancement.
To take this example one step further, if an AI-created track is pretending to be a Taylor Swift song, but the official account for the record label did not create any proof, they can use the lack of proof to deny legitimacy to the counterfeiter. In other words, Postmarks can be used to vouch for the authenticity of the content: if the original recording (the master) doesn’t have a Postmark signed by Taylor, it’s not authentic.
Essentially, what ChainLetter Labs has created using our technology is proactive registration of IP. Our tools will not solve the problem of legacy verification, but they do establish a starting point for verification going forward. As of today, Taylor Swift can assert her rights over her masters, an up-and-coming songwriter or author can assert their rights over their original lyrics, manuscripts, etc.
In summary, the first proof of possession is not proof of ownership, but it gives one a solid claim, especially if they are the originator of a file and no one else has a copy when they create the proof. Also note that proofs can be further enhanced by including items in the file(s) being Postmarked, like digital signatures, watermarks, etc.
Example: Creating AI resistant Materials
Today, artificial intelligence is training off of any data it can scrape up. If one creates an original work without the intent of releasing the rights to the intellectual property, or sensitive information contained within, especially in the age of AI, the need to create durable proof is essential.
With the technology under discussion, one does not need to share their art publicly (where it can be copied) to prove they created it, rather they can create verifiable proof they created the art without divulging anything that holds value (monetary or otherwise) and which could be copied. Even if, after making one’s art public. the AI later trains off this data, one can more easily assert that they created the original. As mentioned above, we also envision a robust “do not train database,” wherein users can simultaneously register their Postmarks to the database upon Postmarking their files, such that this database can be used as an ongoing, public-facing, searchable repository.
Countering Fake, Understated, or Altered Data
In the age of deepfakes and increasingly widespread use of artificial intelligence (AI), the topics discussed in this paper warrant the question, “Can’t I just create fake data and make the proof from it?”
Yes, but then one has a provable “real fake” created on a specific date. Postmarking a file does not automatically increase its legitimacy; the source of the files still needs to be considered when validating or using the data contained within. The time the file is registered as “existing” becomes one more piece of data that can be used to authenticate. For example, our technique and technology applications do not replace other techniques like handwriting analysis, but they do add temporal weight to documents containing handwriting. The source of the file is extremely important.
Example: Altering Lab Results
In discussing fake data, we will use an example concerning a Department of Defense (DoD) robotics laboratory collecting drone imagery that is then ingested into a Geographic Information System (GIS) and analyzed to identify certain objects (in this example, let’s say bright pink semi-trucks). The laboratory is tasked with conducting research, development, testing, and evaluation (RDT&E) of automated target recognition (ATR) algorithms, such that drone data can be analyzed by computers, rather than human eyeballs, saving time during the data analysis stage of operations, while also increasing accuracy (in this example, we’ll say accuracy is defined as the percentage of what the algorithms identify as bright pink semi-trucks are indeed bright pink semi-trucks; often in these cases, the algorithms will also label targets with a confidence rating by way of allowing operators to “triage” and prioritize further investigation—all great data points that could be Postmarked along the way).
The government employees at the laboratory are analyzing four different algorithms being developed by semi-independent parties, to determine which algorithm has the best performance (processing time and accuracy being the two main evaluation criteria). The four parties developing the algorithms and competing for funding are: a national laboratory that employs a mix of government civilians and contractors, another government laboratory of statisticians, all government employees, and two contractors, Lockheed and Leidos.
In the ideal DoD acquisitions process, the operational units ultimately employing this technology would have expressed an operational need via formal request to their respective acquisitions offices at the Pentagon. The Pentagon would then identify possible technologies that could fill the requesting unit’s needs/ capability gaps, and subsequently codify a set of requirements prior to providing funding for the RDT&E to occur at government organizations and/ or bidding out the technology development to defense contractors. These codified requirements will live in a signed requirements document (i.e., a “Capability Developments Document,” or CDD), that outlines the key performance parameters, key system attributes, and additional system attributes needed to meet the operational/ national security need. In our example, the laboratory evaluating the four different ATR algorithms will assess the algorithm’s performance against the requirements and parameters outlined in the CDD.
There are multiple pitfalls with this process, but for our purposes, the greatest is that there is little oversight of the test data being submitted to the overseeing lab during the RDT&E process; these data sets are often used as criteria to continue funding projects, paying salaries, etc. The overseeing lab will surely conduct field exams and trials periodically, but up until those milestones, the semi-independent third parties are able to manipulate variables in their testing. For example, maybe they only submit test results from drone imagery on very visible days, or “cherry-pick” the good sets, or even discount false positives from the test data so that their algorithms performance is artificially enhanced. They might be incentivized to do this for many reasons (including funding and job security, often on the taxpayer’s dime).
If the labs are required to Postmark the files containing collected data as a matter of procedure, it becomes more challenging to tamper with the data to fraudulently come to another conclusion in one’s reports, especially in the case where humans are now relying on machine learning and algorithms to perform jobs previously prone to human error (like ATR using GIS). In other words, the Postmarking procedure creates durable proof of when the data were measured, processed, analyzed, etc. and can be used further to ensure the data—in this case, results of the competing algorithm’s performances which will be used to make decisions on funding, tasking, sometimes even shutting down certain projects—have not been tampered with after the fact in order to manipulate the outcomes in one’s favor. When implemented in all phases of the operations—from collection to downloading to presentation of results, Postmarks act as a durable record of chain of custody to ensure tamper-proof data.
Example: Transcripts
When applying to jobs, schools, volunteer positions, etc., often a candidate must supply a verified or official transcript of their degrees from the institutions that issued them. This cumbersome process must be repeated for every employer or organization/ institute the candidate applies to. Tampered with/ fraudulent transcripts are a realistic risk for employers and institutions, since they cannot trust all applicants to be truthful. The average cost of official transcripts from university registrars or third-party providers (such as National Student Clearinghouse or Parchment) varies, and it depends on whether the school/ institution is willing to cover some of the costs for alumni. Based on our own experience, out of pocket costs can range as high as $35 to have official transcripts sent from a university registrar to a potential employer via a third-party service.
Postmarks offer colleges and universities a cost-saving alternative. Using Postmarks, transcript issuing bodies can create portable, verifiable transcript files that can be verified by anybody who receives them.
Consider the following events:
-
- A college creates proof of a student’s transcript and sends the original file to the student. The file also contains verification instructions inside it.
-
- The student can send that original file to an employer.
-
- Any employer can verify the content ID of the document and follow the instructions to get as much blockchain proof as they require.
-
- The college does not need to keep sending out official transcripts. The student does not need to keep paying for them. The employer can be sure the transcript was not tampered with, if the proof contains the official ID of the college.
-
- The transcript has remained off the public internet during this entire sequence, only needing to exist in the email systems of the applicant and any employers they applied to.
The DoD lab and academic transcript examples are just two of many; from other research or lab data, to students’ standardized test results that might impact their teacher’s job security or bonuses, to important tax or pay documents. Again, one can create a proof for a bad file, but the contents are not validated by our process. What one cannot do, is backdate a tampered file in order to commit fraud.
Conclusion
This paper introduces ChainLetter Lab’s technology and methodology for solving the real-world problem of verifying file trustworthiness. It discusses applications for applying tamper-proof blockchain technology to traditional file verification methods. The possibilities are endless, and by leveraging new, web3 technologies (without the tokenonmics or gambling), we find perhaps one of the greatest utilities in the blockchain to date.
Verifying file trustworthiness in the AI era is complex, demanding innovative solutions beyond traditional methods. This white paper has navigated the intricacies of proving file existence at a specific date, emphasizing the significance of historical possession as a robust claim to ownership.
Distributed immutable and tamper-proof ledgers, such as blockchains, have been highlighted as a pivotal tool in addressing the issues of backdating and fraud. Deploying file hashes as unique identifiers with a low likelihood of collisions further strengthens the integrity of ownership claims.
The reliance on easily manipulatable data, such as screenshots and local security camera footage, underscores the need for a more durable solution. By separating proof from the file itself and employing a comprehensive metadata package, including cryptographic hashes, owner GUIDs, and timestamps, a more robust and secure system for file ownership verification is proposed. ChainLetter Labs has created a consumer-friendly software tool called Postmarks that employs these methods.
The use-case scenarios and examples presented throughout the paper demonstrate the practical applications of this approach, from countering deepfakes and preserving the integrity of original works, to providing verifiable evidence in academic and professional settings. The paper also addresses the limitations of creating proofs for potentially fraudulent files, emphasizing that the technique does not validate the authenticity or legitimacy of the file’s contents.
The integration of blockchain technology further ensures the durability and tamper-resistance of the proofs, offering a decentralized and cryptographically verifiable solution. Furthermore, public access to the proofs through blockchain explorers and independent third-party witnesses adds an extra layer of credibility to the verification process.
In essence, this white paper advocates for a transformative approach to file trustworthiness, urging a departure from unsecure and undesirable practices.
Please do not hesitate to contact us on LinkedIn or via email at [email protected].
Figures
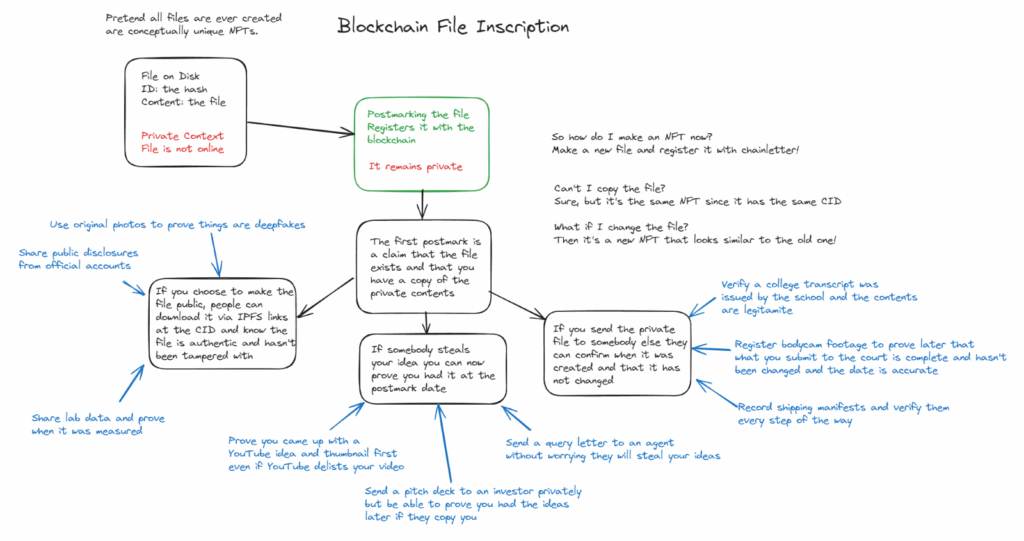
Figure 1. Blockchain File Inscription and Use-Case Commentary
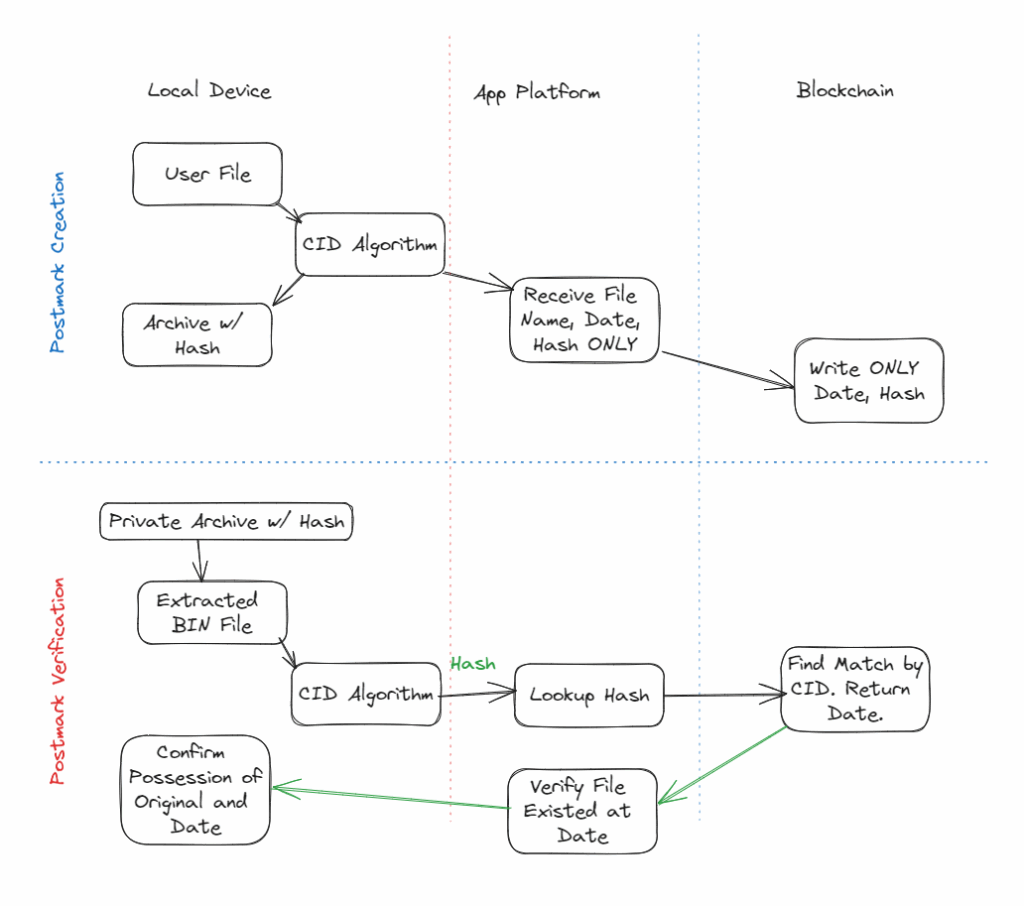
Figure 2. Postmark Creation and Verification Processes
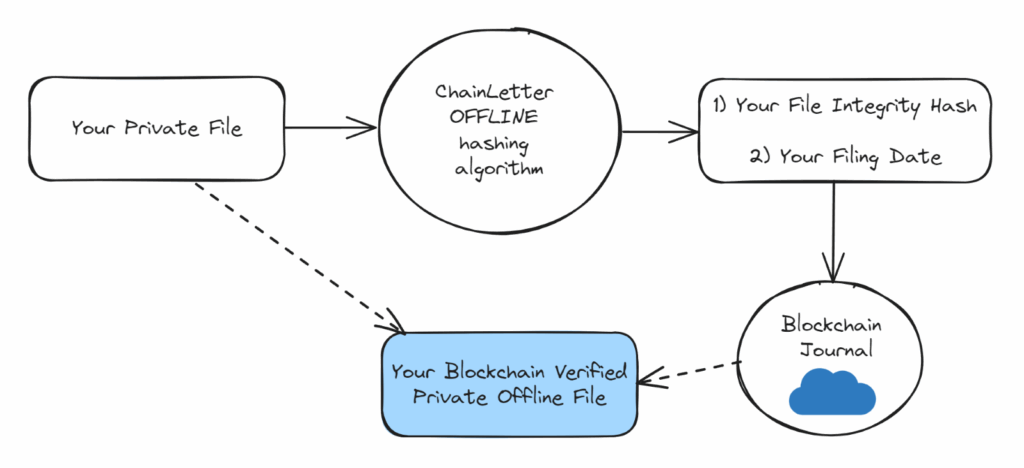
Figure 3. Postmarks Offline File Verification